
[파이썬 웹크롤링] 1. 기본 개념
업데이트:
파이썬을 이용한 웹크롤링을 이해하고 주요 개념 정리
공부 계획
목표기간: 2020년 07월 18일 ~ 7월 31일(프로젝트 기간 포함)
파이썬 웹크롤링을 공부하고 여러 소규모 프로젝트를 만든 후, 포폴용 플젝을 만드는것을 목표로 한다. => 프로젝트는 8월 까지 꼭 만들기! (하반기 시작 전)
웹크롤링(Web Creawling)이란?
웹에서 데이터를 가져오는 행위
이때, 웹에서 가져온 데이터를 내가 원하는 대로 가공하는 것을 파싱(Parsing)이라 한다.
예를 들어, 웹사이트는 HTML 형식으로 작성되었으므로 이를 가져와 보기에 편한 방식(ex.json)로 바꾸어 주는 것이 바로 파싱이다.
스크래핑(Scraping)이란 데이터를 수집하는 모든 과정으로, 크롤링은 스크래핑의 방법 중 하나이다.
=> 이를 정리하면, 웹크롤링을 한다, 파싱한다. == 웹상의 수많은 자료를 스크래핑(크롤링)하여 수집된 데이터를 파싱(가공)해서 내가 원하는 데이터를 추출하는 것
크롤링에 파이썬을 주로 사용하는 이유
- 웹크롤링에 필요한 라이브러리인 fake_useragent, BeautifulSoup, urllib, requests등이 있다.
- 파이썬에는 데이터 수집, 처리, 분석에 유용한 Pandas, TensorFlow(머신러닝) 패키지가 있다.
크롤링을 하기 전 알아야하는 지식
HTTP(Hyper Text Transfer Protocol)
인터넷상에서 데이터를 주고 받을 때 지켜야 하는 통신 규약
= 인터넷상에서 데이터를 주고 받을 수 있는 프로토콜(=규칙)
=> HTTP통신을 통해 인터넷상에서 프로그램이 서로 정보를 주고 받을 수 있다.
사용자가 url에 접속하게 되면 웹브라우저는 해당 페이지의 자원을 가지고 있는 웹서버에 요청(Request)하게 된다.
그럼, 웹서버는 해당 하는 파일을 찾아 다시 웹브라우저로 응답(Response)한다.
HTTP Request 확인 방법
크롬에서 개발자모드(f12) → Network탭 → 아무거나 눌러서 Headers확인
HTTP의 특징
- 요청에 대한 응답 후 접속을 끊는다. => 연결이 지속되지 않는다. (끊임없는 연결시 Ajax사용)
- 통신이 한번 끊기면 현재 상태를 저장하지 않는다.
=> 로그인한 정보를 계속 유지하기 위해 쿠키 등을 사용한다.
HTTP Request 종류
- Get방식
- Post방식
파이썬 라이브러리 - 1)Requests
Python에서는 기본 라이브러리로 urllib가 제공되지만, Requests를 사용하면 좀 더 간결하게 HTTP요청을 할 수 있다.
Requests라이브러리 사용을 위해 pip를 통해 설치해준다.
pip install requests
그리고 웹사이트의 HTML문서 안에 담긴 데이터를 가져오기 위해 Requests 라이브러리를 사용해서 서버에 url을 담아 요청을 보낸다.
import requests
#HTTP get request
response = requests.get("https://www.naver.com/")
.post
.put
.delete
.head
.options
.trace
#HTML 코드 가져오기
html = response.text
print(html)
실행 결과
 url요청 시 메소드로 get이외에도 다양한 메소드들을 사용할 수 있다.
url요청 시 메소드로 get이외에도 다양한 메소드들을 사용할 수 있다.
그리고 코드 실행해주면 요청한 url속 HTML문서 전체 내용을 응답으로 받아 출력할 수 있다.
이제 이 HTML코드에서 나에게 필요한 정보만을 추출해주면 되는데 Requests에서는 이 HTML코드를 파이썬에서 이해할 수 있는 객체 구조로 만들 수 없다.
따라서 이때 BeautifulSoup 라이브러리를 사용한다.
파이썬 라이브러리 - 2)BeautifulSoup(뷰티플숩)
BeautifulSoup 라이브러리는 위에서 출력한 HTML코드를 Python이 이해할 수 있는 객체 구조로 변환할 수 있다. 즉, 데이터 파싱이 가능하다.
그리고 HTML코드를 탐색해서 내가 원하는 데이터만을 쉽게 추출할 수 있는 다양한 메소드를 제공한다.
pip install beautifulsoup4
import requests
from bs4 import BeautifulSoup
response = requests.get("https://www.naver.com/")
html = response.text
print(html)
# html.parse를 사용해서 soup 객체에 넣는다.
soup = BeautifulSoup(html, "html.parser")
이제 soup객체의 메서드를 사용해서 원하는 데이터만을 검색할 수 있다.
이제 cgv사이트에서 순위별 영화 제목만을 추출해보고자 한다.

개발자모드(F12)에서 ctrl+shift+c 후 원하는 영역을 클릭하면 해당하는 태그를 확인할 수 있다.
여기서 영화 제목 태그는 class=’title’인 strong 태그임을 알 수 있다.
import requests
from bs4 import BeautifulSoup
response = requests.get("http://www.cgv.co.kr/movies/")
html = response.text
# html.parse를 사용해서 soup 객체에 넣는다.
soup = BeautifulSoup(html, "html.parser")
for tag in soup.select('strong[class=title]'):
print(tag.text.strip())
위와 같이 select()함수를 사용해서 위에서도 확인했던 class=’title’인 strong 태그만을 가져온다.
그럼 해당하는 태그들이 배열 형태로 가져오게 된다. for문을 통해 각각의 태그에 접근할 수 있다.
그리고 태그에 적힌 텍스트만을 출력해주기 위해 text()를 사용한다.
이대로 출력하면 공백도 함께 출력되므로 이를 제거해주기 위해 strip()을 사용한다.
출력 결과는 다음과 같다.
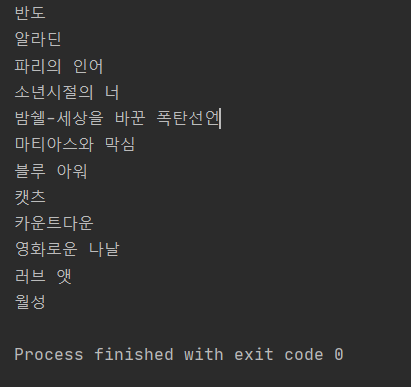
성공적으로 크롤링이 완성된것을 볼 수 있다.
이외에 bs4에서 제공하는 다양한 메소드들을 실습하고, 다양한 케이스에서 활용할 수 있도록 하자.